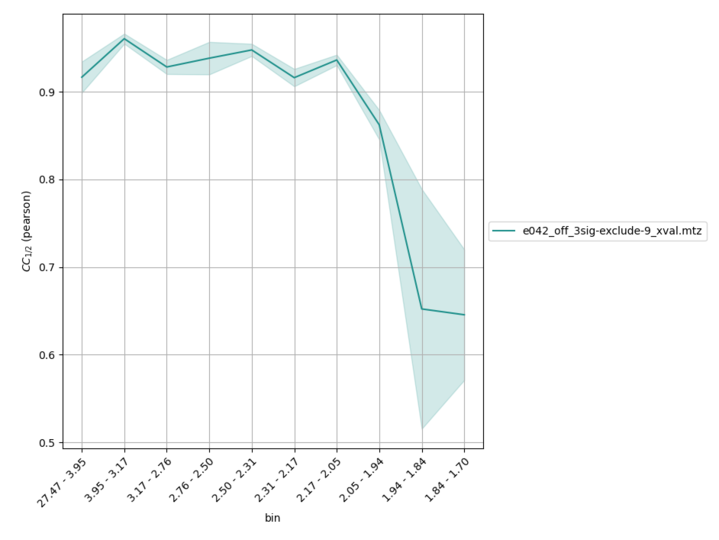
With a bit of effort, scaled intensity, .si files from precognition can be used to estimate CC_{1/2}. The prerequisites for this are that you have reciprocalspaceship and rs-booster installed. The following steps are necessary
- Convert the
.sifile to a.mtzfile using thesi2mtz.pyscript - Convert the
.mtzfile to a careless_xval.mtzformat using themtz2xval.pyscript. - Finally run
rs.cchalfwith the desired settings to get the CC_{1/2}
Given an input file, e042_off_3sig-exclude-9.si, calculate CC_{1/2} by running the following commands,
./si2mtz.py --cell 34 45 98 90 90 90 --space-group 19 e042_off_3sig-exclude-9.si
./mtz2xval.py --repeats 10 e042_off_3sig-exclude-9.mtz
rs.cchalf --method=pearson --show e042_off_3sig-exclude-9_xval.mtz
si2mtz.py
This is a simple script for convert precognition, .si files into .mtz files for downstream processing in rs. Note that the read_precognition function definition can be omitted after the next reciprocalspaceship release. In version 1.0.7. rs.read_precognition will natively support .si files.
#!/usr/bin/env python
import warnings
import gemmi
import pandas as pd
from reciprocalspaceship import DataSet,DataSeries,concat
import numpy as np
def read_precognition(hklfile, spacegroup=None, cell=None, logfile=None):
"""
Initialize attributes and populate the DataSet object with data from
a precognition hkl or ii file of reflections. This is the output format used by
Precognition when processing Laue diffraction data.
Parameters
----------
hklfile : str or file
name of an hkl, si, or ii file or a file object
spacegroup : str or int
If int, this should specify the space group number. If str,
this should be a space group symbol
cell : tuple or list of floats
Unit cell parameters
logfile : str or file
name of a log file to parse to get cell parameters and spacegroup. Only
used when spacegroup and/or cell are not explicitly provided.
"""
# Read data from HKL file
if hklfile.endswith(".hkl"):
usecols = [0, 1, 2, 3, 4, 5, 6]
F = pd.read_csv(
hklfile,
header=None,
sep="\\s+",
names=["H", "K", "L", "F(+)", "SigF(+)", "F(-)", "SigF(-)"],
usecols=usecols,
)
mtztypes = ["H", "H", "H", "G", "L", "G", "L"]
# Check if any anomalous data is actually included
if len(F["F(-)"].unique()) == 1:
F = F[["H", "K", "L", "F(+)", "SigF(+)"]]
F.rename(columns={"F(+)": "F", "SigF(+)": "SigF"}, inplace=True)
mtztypes = ["H", "H", "H", "F", "Q"]
# Read data from II file
elif hklfile.endswith(".ii"):
usecols = range(10)
F = pd.read_csv(
hklfile,
header=None,
sep="\\s+",
names=[
"H",
"K",
"L",
"Multiplicity",
"X",
"Y",
"Resolution",
"Wavelength",
"I",
"SigI",
],
usecols=usecols,
)
mtztypes = ["H", "H", "H", "I", "R", "R", "R", "R", "J", "Q"]
# Read data from SI file
elif hklfile.endswith(".si"):
usecols = range(7)
F = pd.read_csv(
hklfile,
header=None,
sep="\\s+",
names=[
"H",
"K",
"L",
"Wavelength",
"SigWavelength",
"I",
"SigI",
],
usecols=usecols,
)
mtztypes = ["H", "H", "H", "R", "R", "J", "Q"]
if logfile is not None:
warnings.warn("Ignoring logfile, as logfiles are not supported for .si format.")
logfile = None
# Limit use to supported file formats
else:
raise ValueError("rs.read_precognition() only supports .ii, .si, and .hkl files")
# If logfile is given, read cell parameters and spacegroup
# Assign these as temporary variables, and determine priority later.
if logfile:
from os.path import basename
with open(logfile, "r") as log:
lines = log.readlines()
# Read spacegroup
sgline = [l for l in lines if "space-group" in l][0]
spacegroup_from_log = [s for s in sgline.split() if "#" in s][0].lstrip("#")
# Read cell parameters
block = [i for i, l in enumerate(lines) if basename(hklfile) in l][0]
lengths = lines[block - 19].split()[-3:]
a, b, c = map(float, lengths)
angles = lines[block - 18].split()[-3:]
alpha, beta, gamma = map(float, angles)
cell_from_log = (a, b, c, alpha, beta, gamma)
dataset = DataSet(F)
dataset = dataset.astype(dict(zip(dataset.columns, mtztypes)))
dataset.set_index(["H", "K", "L"], inplace=True)
# Set DataSet attributes
# Prioritize explicitly supplied arguments
if cell:
dataset.cell = cell
elif logfile:
dataset.cell = cell_from_log
if spacegroup:
dataset.spacegroup = spacegroup
elif logfile:
dataset.spacegroup = spacegroup_from_log
if cell and spacegroup and logfile:
warnings.warn("Ignoring logfile, as cell and spacegroup are both provided")
return dataset
if __name__=="__main__":
from argparse import ArgumentParser
parser = ArgumentParser("Convert `.si` files from precognition into mtzs")
parser.add_argument("sifile", nargs="+")
parser.add_argument("--cell", nargs=6, type=float, default=None)
parser.add_argument("--space-group", type=str, default=None)
parser.add_argument("--repeats", type=int, default=0, help='Number of times to repeat random half dataset assignment')
parser = parser.parse_args()
for si in parser.sifile:
hkl = read_precognition(si)
hkl.cell = parser.cell
hkl.spacegroup = parser.space_group
outfile = si.removesuffix(".si") + ".mtz"
hkl.write_mtz(outfile)
mtz2xval.py
#!/usr/bin/env python
import warnings
import gemmi
import pandas as pd
import reciprocalspaceship as rs
import numpy as np
from argparse import ArgumentParser
parser = ArgumentParser("Create a file for rs.cchalf from scaled, unmerged intensities")
parser.add_argument("mtz")
parser.add_argument("--repeats", type=int, default=1, help='Number of times to repeat random half dataset assignment')
parser.add_argument("--sigma-key", type=str, default=None, help='Sigma column to use.')
parser.add_argument("--intensity-key", type=str, default=None, help='Sigma column to use.')
parser.add_argument("--anomalous", action='store_true', help='Treat as anomalous data, keeping Friedel mates separate')
parser = parser.parse_args()
ds = rs.read_mtz(parser.mtz)
if parser.sigma_key is None:
sigma_keys = ds.dtypes[ds.dtypes=='Q'].keys()
if len(sigma_keys) > 1:
raise ValueError("Multiple uncertainty columns detected. Use `--sigma-key` to specify the desired column")
elif len(sigma_keys) == 0:
raise ValueError("No uncertainty columns detected. Use `--sigma-key` to specify the desired column")
else:
sigma_key = sigma_keys[0]
else:
sigma_key = parser.sigma_key
if parser.intensity_key is None:
intensity_keys = ds.dtypes[ds.dtypes=='J'].keys()
if len(intensity_keys) > 1:
raise ValueError("Multiple uncertainty columns detected. Use `--intensity-key` to specify the desired column")
elif len(intensity_keys) == 0:
raise ValueError("No uncertainty columns detected. Use `--intensity-key` to specify the desired column")
else:
intensity_key = intensity_keys[0]
else:
intensity_key = parser.intensity_key
out = []
for r in range(parser.repeats):
idx = np.random.random(len(ds)) > 0.5
half1,half2 = ds[idx],ds[~idx]
half1 = rs.algorithms.merge(half1, intensity_key, sigma_key, parser.anomalous)
half2 = rs.algorithms.merge(half2, intensity_key, sigma_key, parser.anomalous)
half1['repeat'], half2['repeat'] = r, r
half1['half'],half2['half'] = 0, 1
out.extend([half1, half2])
out = rs.concat(out)
out = out.rename(columns={
intensity_key : 'F',
sigma_key : 'SigF',
})
out = out.infer_mtz_dtypes()
out.write_mtz(
parser.mtz.removesuffix('.mtz') + '_xval.mtz'
)